Essential系列-ceph对象存储/日志文件系统是如何工作的(二)
How to build storage infrastruction?
基于unix文件系统是操作系统中简单易懂的部分。
这是由它的设计决定的-一切皆是文件。
当前的文件系统基本分为两类:
-
基于事务或日志(journal)的写方式,它提供了更好的高可用性
-
不含日志的写方式
不使用日志(no journal)的文件系统 ext2的工作方式
文件系统中的存储概念
- block
一个逻辑块(block)是最小的能被文件系统分配的存储单元,以用字节(byte)为单位。单个文件可以包含多个blocks
- 逻辑卷(local volume)
一个磁盘分区或者整个物理磁盘
- inode
文件元数据(meta data)的存储数据结构。
文件数据本身以外的数据,比如 时间戳、ownership 信息,访问权限,安全信息,文件大小以及存储的位置。
- directory
目录,一种特别的文件,包含内容文件的inode元数据列表。
基本面上看,文件系统的写文件过程至少包含了2个IO过程:
-
inode(文件元数据)的写入过程
-
实际文件内容写入对应的block的过程
这里面存在2个问题:
先写元数据还是先写实际数据?
如果在任意一个IO中,出现了异常中断应该如何处理?
这两个问题是所有多重IO系统面临的通用问题
Journaling
在linux系统中,一个文件的元信息有inode结构维持。
inode的主要结构信息:
owner : ****owner username****
permissions : read-write
size : 1
pointer : 4 # 指向block
pointer : null
pointer : null
pointer : null
一次IO要经过三次IO操作:
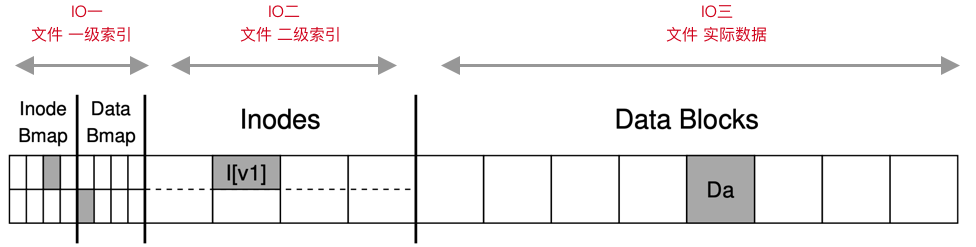
-
Bitmap 结构描述了inode和block的对应关系
-
inode结构描述block的具体信息
-
block存储数据本身的二进制内容
以上三次独立的IO过程,任意一个阶段出现异常,都会引起数据的丢失或者不一致的情况:
1) Block 被写入磁盘,但是Inode信息没有写入或者更新
2) inode被更新了,但是block没有写完整
3) bitmap更新了,但是剩余两个信息不完整
以上三个问题归结为IO一致性问题
目前有以下几种解决方式:
一、使用文件系统扫描工具 fsck
这是一种亡羊补牢的方式。
File system checker(文件系统扫描)
unix系统中典型的文件扫描工具是fsck(注: 在linux系统启动过程中,如果之前异常关机,会启动这个扫面程序)
fsck的确认项动作:
-
superblock 超级块检查
-
free blocks 检查已分配的区块和inode以及bitmap的对应关系,如果出现异常,重建元数据信息
-
inode 完整新检查 && inode重复检查
-
目录检查
-
坏块检查
二、使用日志journaling
日志文件系统使用的常规手段是 Wal, 很面熟的词,因为这是数据库系统输入写入和实现日志分发功能的常用手段,全称是write-ahead loging。
wal的思想是:
实际执行写入动作之前,做一个动作笔记或者action list 并存在一个地方。这一步操作成为写前日志。postgresql的默认存贮位置是DATA/wal
这一步动作的目的是先记录动作的所有raw data,如果在接下来的动作中,任意一步失败了,可以通过回放解决。这也是很多事务型的操作常用的设计手段。
ext3是经典的、常用的基于journaling文件系统。
ext4实现完整的、state safe 状态安全的日志原子性写入操作。

以上,可归结为三个步骤:
- Action 1
Journal write transaction 开启一个日志写入事务
- Action 2
Journal commit, 日志内的内容写入完成以后,提交事务。
- Action 3
Checkpoint, 这一步讲更新的内容写入磁盘上的最终的位置,包括数据本身和元数据。
这样,日志文件以一个事务的数据结构大小为窗口,向前推进,如果在数据写入磁盘的过程中出现异常,仅仅replay这个事务即可。
这里的问题是,随着文件写入越来越多,日志文件会越来越大,如何处理这种问题?
答案是 使用循环日志

- Action 4
回收已经写入成功的事务占用的磁盘空间。
总结,这种写入方式确实实现了状态安全的写入过程,但是问题是,数据写入了2次。
更优化、最常用的方式是,在事务提交中,不写入数据本身,仅仅写入数据的meta data。
NTFS, XFS, EXT3 都实现了这种方式。
总结
基于日志journal的文件写入方式,也用在mysql和postgresql数据持久化过程之中。是一种通用思想。
ceph的架构目标是实现存储Infrastruction, 它在journing之上又构建了一层meta data,目标是实现存储的任务水平扩展,同时保证原子性。
